翻訳タブ
翻訳エンジン設定をカスタマイズします。
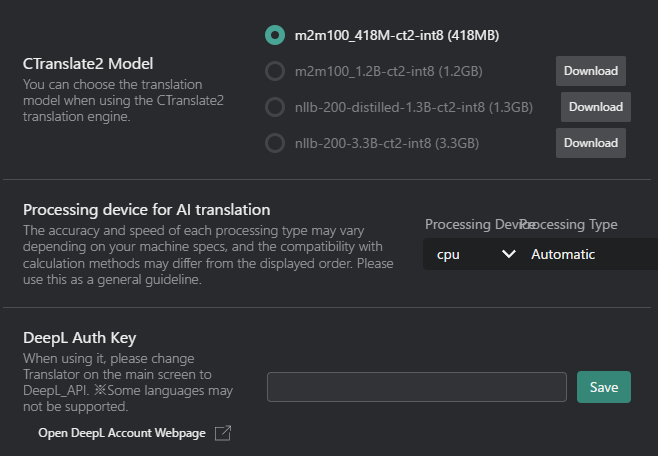
CTranslate2 モデルと設定
-
CTranslate2 モデル:オフラインの文字起こし/翻訳用ローカルモデルを選択します(利用可能な場合)。
モデル名 サイズ 説明 m2m100_41M-ct2-int8 418MB 100の言語をサポートするFacebookの多言語機械翻訳モデル。 m2m100_1.2B-ct2-int8 1.2GB 翻訳品質が向上したFacebook M2M100モデルのより大きいバージョン。 nllb-200-distilled-1.3B-ct2-int8 1.3GB 200言語をサポートし、高精度のMetaの NLLB-200蒸留モデル。 nllb-200-3.3B-ct2-int8 3.3GB 最高の翻訳品質のための完全版Meta NLLB-200モデル。 - ダウンロードボタン:まだモデルをダウンロードしていない場合、このボタンをクリックしてダウンロードします。
-
AI翻訳用の処理デバイス:翻訳タスク用の処理デバイスを選択します。
-
処理デバイス:
- CPU:翻訳タスクにコンピュータのメインプロセッサを使用します。
- GPU:潜在的に高速な処理のためグラフィックスカードを利用します(サポートされている場合)。
ヒントCTranslate2モデルでGPUを使用したい場合は、VRCTをCUDAバージョンに変更する必要があります。
詳細はCUDAバージョンでVRCTを再インストールページを参照してください。 -
処理タイプ:
タイプ 精度 速度 説明 自動 自動 自動 ハードウェア機能に基づいて最適な処理タイプを自動選択します。 int8 低 高速 高速処理と低いメモリ使用量のための8ビット整数精度を使用します。 int8_float16 中 高速 速度と精度のバランスのために8ビット整数と16ビット浮動小数点精度の組み合わせを使用します。 int8_bfloat16 中 高速 互換性のあるハードウェアでの効率的な処理のために8ビット整数とbfloat16精度の組み合わせを使用します。 int8_float32 高 中 より高い精度のために8ビット整数と32ビット浮動小数点精度の組み合わせを使用します。 int16 低 中 メモリ使用量が少なくなるように16ビット整数精度を使用します。 bfloat16 中 中 互換性のあるハードウェアでの効率的な処理のためにbfloat16精度を使用します。 float16 中 中 速度と精度のバランスのために16ビット浮動小数点精度を使用します。 float32 高 低速 最高精度のために32ビット浮動小数点精度を使用します。 ヒント最適な処理タイプはハードウェア環境によって異なります。
あなたに最適な処理タイプを見つけるために、複数のオプションを試してください。
-
API
DeepLやOpenAIなどのサービスの有料/プロ機能を使用している場合は、APIキーを入力します。
DeepL API
- DeepL APIキー:DeepL翻訳サービス使用のためのAPIキーを入力します。
Plamo API
- Plamo APIキー:Plamo翻訳サービス使用のためのAPIキーを入力します。
- Plamoモデルを選択:翻訳用に特定のPlamoモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はPlamoドキュメントを参照してください。
Gemini API
- Gemini APIキー:Gemini翻訳サービス使用のためのAPIキーを入力します。
- Geminiモデルを選択:翻訳用に特定のGeminiモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はGeminiドキュメントを参照してください。
OpenAI API
- OpenAI APIキー:OpenAI翻訳サービス使用のためのAPIキーを入力します。
- OpenAIモデルを選択:翻訳用に特定のOpenAIモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はOpenAIドキュメントを参照してください。
Groq API
- Groq APIキー:Groq翻訳サービス使用のためのAPIキーを入力します。
- Groqモデルを選択:翻訳用に特定のGroqモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はGroqドキュメントを参照してください。
Open Router API
- Open Router APIキー:Open Router翻訳サービス使用のためのAPIキーを入力します。
- Open Routerモデルを選択:翻訳用に特定のOpen Routerモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はOpen Routerドキュメントを参照してください。
LM Studio API
- LM Studio接続を確認:ローカルAI翻訳用のLM Studioサーバーへの接続をテストします。
- LM Studioサーバーが実行中でアクセス可能であることを確認してください。
- LM Studio URL:ローカルAI翻訳用のLM StudioサーバーのURLを指定します。
- デフォルト:
http://127.0.0.1:1234/v1
- デフォルト:
- LM Studio モデルを選択:翻訳用に特定のLM Studioモデルを選択します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はLM Studioドキュメントを参照してください。
Ollama API
- Ollama接続を確認:ローカルAI翻訳用のOllamaサーバーへの接続をテストします。
- Ollamaサーバーが実行中でアクセス可能であることを確認してください。
- Ollama モデルを選択:翻訳用にOllamaモデルを指定します。
- さまざまなモデルが異なる言語と目的のために利用可能です。
- 詳細はOllamaドキュメントを参照してください。