文字起こしタブ
コンフィグウィンドウの文字起こしタブで、マイクおよびスピーカー音声の文字起こし設定をカスタマイズできます。
マイク文字起こし
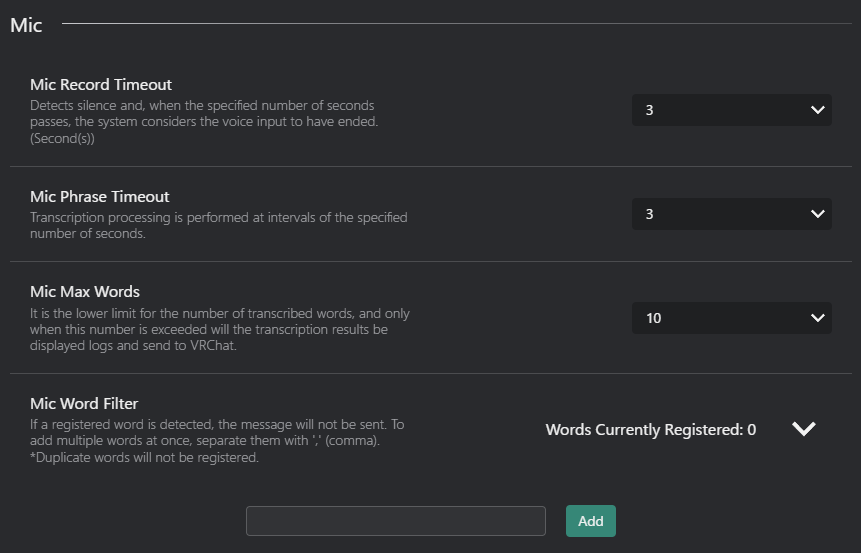
- マイク記録タイムアウト :マイク記録のタイムアウト期間を設定します。
- 無音を検出し、指定された秒数が経過すると、システムは音声入力が終了したと見なします。(秒)
- マイク句フレーズ検出タイムアウト :マイク句フレーズ検出のタイムアウト期間を設定します。
- 文字起こし処理は指定された秒数の間隔で実行されます。
- マイク最大単語数: マイク文字起こしの最大単語数を設定します。
- 文字起こしされた単語の数の下限であり、この数を超えた場合のみ、文字起こしの結果がログに表示され、VRChatに送信されます。
- マイク単語フィルタ: マイク文字起こしの単語フィルタを有効または無効にします。
- 登録された単語が検出された場合、メッセージは送信されません。複数の単語を一度に追加するには、それらを「,」(コンマ)で区切ってください。\n重複する単語は登録されません。
スピーカー文字起こし
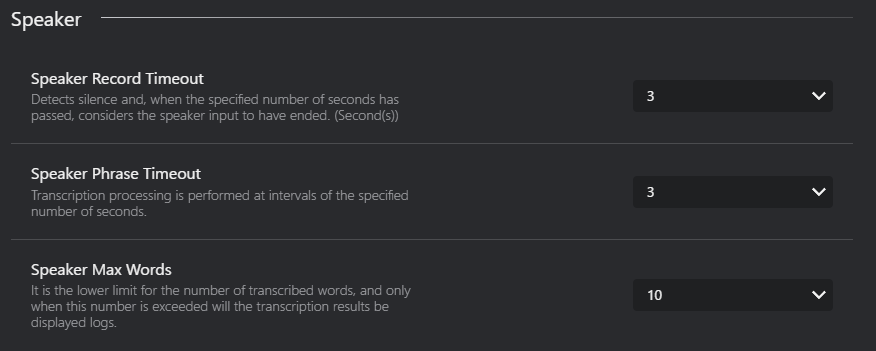
- スピーカー記録タイムアウト :スピーカー記録のタイムアウト期間を設定します。
- 無音を検出し、指定された秒数が経過すると、スピーカー入力が終了したと見なします。(秒)
- スピーカー句フレーズ検出タイムアウト :スピーカー句フレーズ検出のタイムアウト期間を設定します。
- 文字起こし処理は指定された秒数の間隔で実行されます。
- スピーカー最大単語数: スピーカー文字起こしの最大単語数を設定します。
- 文字起こしされた単語の数の下限であり、この数を超えた場合のみ、文字起こしの結果がログに表示されます。
文字起こしエンジン
-
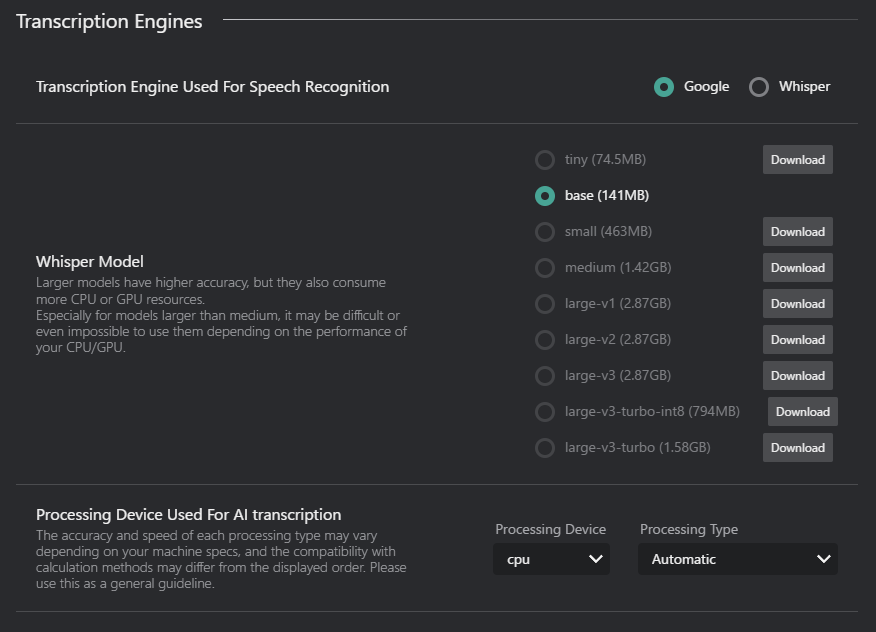
音声認識に使用する文字起こしエンジン: 音声からテキストへの変換に使用するエンジンを選択します(例:Google、Whisper)。
-
Whisperモデル: Whisperが選択されている場合、文字起こし用のWhisperモデルを選択します。
モデル名 サイズ 説明 tiny 74.5 MB 最速、最も精度が低い base 141 MB 高速、精度が低い small 463 MB 速度と精度のバランス medium 1.42 GB 遅い、精度が高い large-v1 2.87 GB 最も遅い、最高精度 large-v2 2.87 GB 最も遅い、最高精度 large-v3 2.87 GB 最も遅い、最高精度 large-v3-turbo-int8 794MB 遅い、精度が高い、パフォーマンスに最適化 large-v3-turbo 1.58GB 最も遅い、最高精度、パフォーマンスに最適化 - ダウンロードボタン:選択されたWhisperモデルをまだダウンロードしていない場合、このボタンをクリックしてダウンロードします。
-
AI文字起こしに使用する処理デバイス: 文字起こしタスク用の処理デバイスを選択します。
-
処理デバイス:
- CPU:文字起こし処理にコンピュータのCPUを使用します。
- GPU:文字起こし処理にコンピュータのGPUを使用します(利用可能な場合)。
ヒントCTranslate2モデルでGPUを使用したい場合は、VRCTをCUDAバージョンに変更する必要があります。
詳細はCUDAバージョンでVRCTを再インストールページを参照してください。 -
処理タイプ:
タイプ 精度 速度 説明 自動 自動 自動 ハードウェア機能に基づいて最適な処理タイプを自動選択します。 int8 低 高速 高速処理と低いメモリ使用量のための8ビット整数精度を使用します。 int8_float16 中 高速 速度と精度のバランスのために8ビット整数と16ビット浮動小数点精度の組み合わせを使用します。 int8_bfloat16 中 高速 互換性のあるハードウェアでの効率的な処理のために8ビット整数とbfloat16精度の組み合わせを使用します。 int8_float32 高 中 より高い精度のために8ビット整数と32ビット浮動小数点精度の組み合わせを使用します。 int16 低 中 メモリ使用量が少なくなるように16ビット整数精度を使用します。 bfloat16 中 中 互換性のあるハードウェアでの効率的な処理のためにbfloat16精度を使用します。 float16 中 中 速度と精度のバランスのために16ビット浮動小数点精度を使用します。 float32 高 低速 最高精度のために32ビット浮動小数点精度を使用します。 ヒント最適な処理タイプはハードウェア環境によって異なります。
あなたに最適な処理タイプを見つけるために、複数のオプションを試してください。
-
追加設定(Whisperモデル)

- マイク平均ログ確率: マイク文字起こしの平均ログ確率閾値を設定します。
- マイク音声なし確率: マイク文字起こしの音声なし閾値を設定します。
- スピーカー平均ログ確率: スピーカー文字起こしの平均ログ確率閾値を設定します。
- スピーカー音声なし確率: スピーカー文字起こしの音声なし閾値を設定します。
ヒント
平均ログ確率
セグメントで生成されたすべてのトークンの平均ログ確率。
より高い値(0に近い)はより高い信頼度を示します。
より低い値(例:-1.0以下)は低い信頼度または誤認識の可能性を示唆しています。
音声なし確率
入力オーディオに音声が含まれていない確率。
1.0に近い値は無音または背景ノイズを示します。
このパラメータは通常、静かな期間中の誤検出をフィルタリングするために使用されます。